Om ervoor te zorgen dat jouw website goed wordt weergegeven binnen de zoekmachine van Google, zijn er twee essentiële onderdelen: crawling en indexering. Voor Google zijn deze onderdelen cruciaal om je website te doorzoeken en correct weer te geven binnen de zoekresultaten (SERP). Als de termen crawlen en indexatie nieuw voor je zijn, kan dit blog je helpen om het te begrijpen. We leggen uit hoe de onderdelen werken en waarom ze van groot belang zijn voor de zichtbaarheid van jouw website.

Wat is Crawlen?
Crawlen is het proces waarbij zoekmachines jouw website doorzoeken om pagina’s te ontdekken en te analyseren. Deze zoekmachine crawlers worden spiders of (crawl) bots genoemd. Zoekmachines gebruiken de webcrawlers om automatisch door de websites te navigeren om informatie te verzamelen en te begrijpen wat er op de pagina’s staat.
Ook worden de linkjes op de je website gevolgd om de relatie tussen de verschillende pagina’s op je website te begrijpen. Hierdoor kunnen zoekmachines bepalen welke inhoud op jouw website staat en wanneer het relevant is om jouw pagina aan te bieden binnen de zoekresultaten.
Op basis van de informatie die de webcrawlers verzamelen, kan de zoekmachine jouw website aan gebruikers tonen. De zoekmachines tonen jouw pagina in de zoekresultaten (SERP) wanneer bezoekers zoeken naar onderwerpen die overeenkomen met de inhoud van jouw pagina. Het is belangrijk om te begrijpen hoe zoekmachines crawls uitvoeren om je pagina’s te vinden en analyseren.
Hoe werkt het crawl budget
Het crawl budget verwijst naar het aantal pagina’s dat een crawler elke keer dat de bot langskomt, kan crawlen. Dit is belangrijk omdat zoekmachines slechts een beperkt aantal pagina’s per website per keer kunnen crawlen. Als jouw website veel pagina’s heeft, kan het zijn dat niet alle pagina’s worden doorzocht.
Google wil niet dat jouw website offline gaat tijdens crawlen en daarom geeft het per website een bepaald crawl budget af. Dit budget wordt gebaseerd op basis van de volgende factoren: website-structuur, de frequentie van updates, de kwaliteit van de inhoud, de snelheid van de server, het aantal links, instellingen in het robots.txt-bestand en XML-sitemap.
Daarnaast worden ook de CSS- en JavaScript-bestanden gecrawld om te begrijpen hoe de pagina eruitziet en hoe deze functioneert. Afbeeldingen worden geïndexeerd op basis van hun alt-tekst en video’s en andere media worden geëvalueerd, hiervoor is het belangrijk dat ze goed zijn geoptimaliseerd met beschrijvingen en gestructureerde gegevens.
Als niet alle pagina’s kunnen worden opgehaald, is het van belang om te onderzoeken hoe je het crawl budget kunt verhogen.
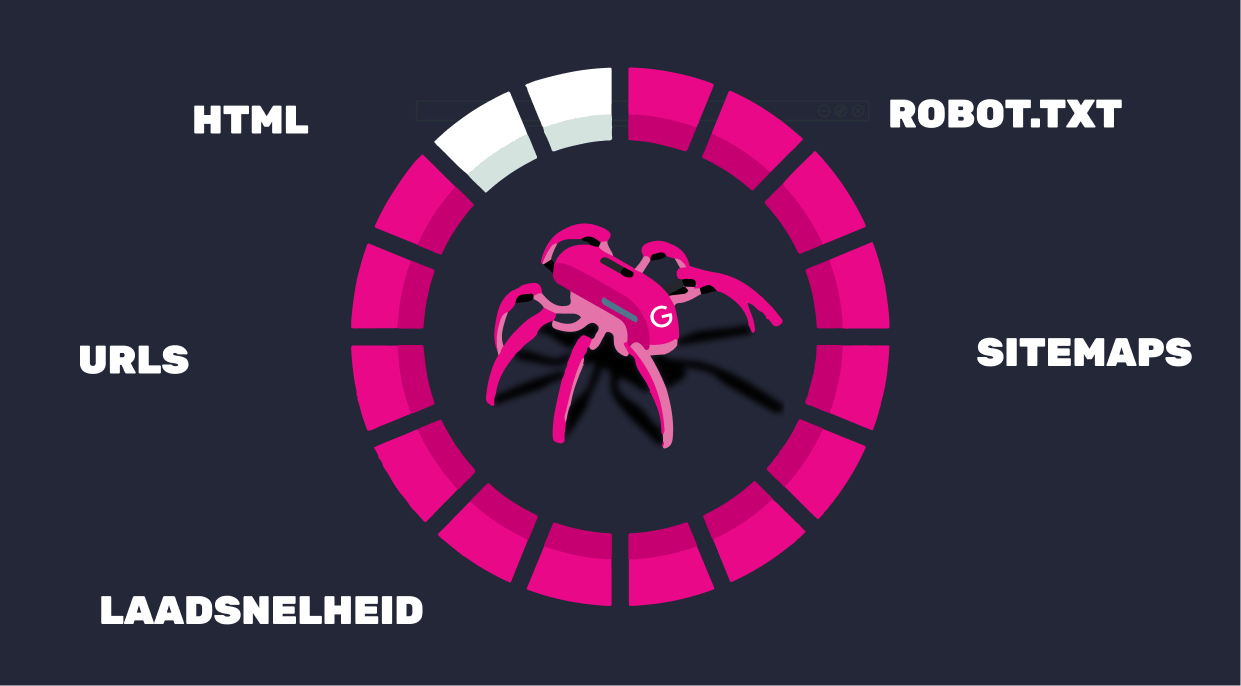
Crawl budget verhogen
Om ervoor te zorgen dat jouw website optimaal wordt gecrawld, kun je het crawl budget verhogen door de volgende stappen te optimaliseren:
- Verbeter de laadsnelheid van je website (Core Web Vitals): Een snellere website zorgt ervoor dat crawlers efficiënter door je pagina’s kunnen navigeren (zie ons eerder geschreven blog met meer informatie over CORE web vitals).
- Optimaliseer de interne linkstructuur: Zorg ervoor dat pagina’s goed met elkaar zijn verbonden. Dit helpt crawlers makkelijker en sneller de website te doorzoeken.
- Voorkom 3xx- en 4xx-meldingen: Verwijder of herstel links die leiden tot redirects of een niet bestaande link. Onnodige crawls van irrelevante links gaan ten koste van het crawl budget en kunnen ertoe leiden dat belangrijke pagina’s worden overgeslagen.
- Optimaliseer je robots.txt-bestand: Zorg ervoor dat dit bestand helder en gestructureerd is, zodat crawlers direct weten welke delen van je website ze moeten doorzoeken en welke ze moeten negeren. (Hier gaan we later dieper op in)
- Zorg voor een duidelijke XML-sitemap: Het is essentieel om een goed gestructureerde XML-sitemap te hebben. Een duidelijke sitemap helpt zoekmachines om de inhoud van je website efficiënt te begrijpen en te indexeren.
Robots.txt
Met de robots.txt bestand kan je aangeven welke delen van de website of pagina’s niet hoeven worden gecrawld. Hiervoor kan je een regel met ‘Disallow’ instellen als bijvoorbeeld een bepaald teken erin staat. Dit kan jezelf bepalen en aanmaken, zolang dit maar goed is ingesteld en het begrepen kan worden tijdens het crawlen. Als je wilt weten hoe je dit bij je eigen website kunt controleren, kun je eenvoudig je domeinnaam gevolgd door /robot.txt invoeren in de adresbalk. Bijvoorbeeld: www.(domeinnaam)/robots.txt. Hiermee kun je precies zien welke richtlijnen je hebt ingesteld voor crawlers.
Verder wordt er gekeken naar meta-robots-tags en canonical tags om te bepalen of pagina’s geïndexeerd moeten worden en welke versie van een pagina als de belangrijkste moet worden beschouwd.
Zelf website crawlen
Er zijn tools beschikbaar die je helpen met het crawlen van je eigen website. Door je eigen website te crawlen, kun je ontdekken tegen welke problemen een crawler kan aanlopen tijdens het indexeren. Een voorbeeld hiervan is het aantal meldingen van 3xx of 4xx links die naar jouw website verwijzen of met jouw website zijn verbonden.
Hieronder twee voorbeelden van tools waarmee jij zelf je website kan crawlen:
- Screaming Frog SEO Spider
Een veelgebruikte tool die een diepgaande analyse biedt van je website. Met Screaming Frog kun je onder andere metadata, statuscodes en interne links bekijken. Daarnaast zie je ook of er duplicate content staat op jouw website. - Ahrefs Site Audit
Ahrefs biedt een site-audit tool waarmee je je website kunt crawlen om technische problemen te identificeren. Het is vooral handig voor het vinden van gebroken links en andere SEO-gerelateerde kwesties.
Wat is indexeren?
Wanneer jouw website is gecrawld, gaat Google pagina’s indexeren. Google indexering betekent dat de informatie die tijdens de crawl is opgehaald wordt verzameld en opgeslagen in de database. De database is een digitale archief waarin pagina’s zijn opgeslagen, zodat ze snel kunnen worden weergegeven wanneer iemand een relevante zoekopdracht uitvoert.
Wanneer je een link een ‘Nofollow’ tag meegeeft, geef je aan dat de link niet gevolgd moet worden, of de pagina waar de link naartoe verwijst. Dit gebruik je wanneer je geen waarde aan de link wilt toekennen. Als je daarnaast ook wilt voorkomen dat de pagina wordt geïndexeerd, moet je de pagina voorzien van een ‘noindex’-tag. Op deze manier zorg je ervoor dat alleen waardevolle pagina’s worden opgenomen tijdens het crawlen en indexeren.

Hoe vaak indexeert Google een site?
Een website wordt pas door geïndexeerd nadat deze is gecrawld. Grote en actieve websites worden vaker opnieuw geïndexeerd omdat ze vaker gecrawld worden dan kleinere websites. Dit komt doordat grotere websites vaak meer kwalitatieve backlinks hebben, wat ervoor zorgt dat zoekmachines ze sneller oppikken. Het hoge aantal kwalitatieve backlinks geeft crawlers dat de website of pagina belangrijk is, wat leidt tot een hoger crawlbudget.
Als je wijzigingen op je website hebt doorgevoerd, kan het even duren voordat de wijziging zijn opgemerkt en opnieuw geïndexeerd worden. Wil jij je website opnieuw laten indexeren door Google, dan kun je het proces versnellen door een verzoek in te dienen via Search Console. Houd er wel rekening mee dat het alsnog van afhangt wanneer de webcrawlers je website komen crawlen. Het aanvragen van een herindexering betekent dat de pagina boven in het rijtje komt te staan op het moment dat de crawler weer langs jouw domein komt.
Website laten indexeren door Google
In Search Console kun je precies zien hoeveel pagina’s door zijn geïndexeerd en of er problemen zijn met pagina’s die niet zijn geïndexeerd. Als je merkt dat bepaalde pagina’s niet worden geïndexeerd, is het belangrijk om dit snel op te lossen, zodat alle pagina’s van je website worden geïndexeerd. Door je sitemap toe te voegen in Google Search Console laat je weten welke URL’s belangrijk zijn en je wilt dat er geïndexeerd worden.
Benieuwd hoe wij jou kunnen helpen met het verhogen van je crawlbudget?
Neem contact met onze SEO specialisten om samen te kijken naar verbeterpunten binnen jouw shop om je crawlbudget te optimaliseren!